Java Stream流
1.概述
1.1.概念
- Stream不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的Iterator。原始版本的Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的Stream,用户只要给出需要对其包含的元素执行什么操作,比如,“过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream会隐式地在内部进行遍历,做出相应的数据转换。Stream就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
- 而和迭代器又不同的是,Stream可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个item读完后再读下一个item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream的并行操作依赖于Java7中引入的Fork/Join框架(JSR166y)来拆分任务和加速处理过程。
- Stream 的另外一大特点是,数据源本身可以是无限的。
1.2.Stream流的特性
- 不存储数据[按照特定的规则对数据进行计算,一般会输出结果]
- 不会改变数据源[通常情况下会产生一个新的集合或一个值]
- 具有延迟执行特性[只有调用终端操作时,中间操作才会执行]
1.3.Stream流的作用
结合Lambda表达式,简化集合、数组操作,提高代码的效率。
1.4.Stream流的使用步骤
- 获取数据源,将数据源中的数据读取到流中

- 对流中的数据进行各种各样的处理[筛选、过滤……] 中间操作->方法调用完毕后会返回另一个流,还可以继续调用其他方法[建议使用链式编程]
- 对流中的数据进行整合处理[遍历、统计……] 终端操作->方法调用完毕后,流就关闭了,不能再调用其他方法
2.Stream的生成
2.1.Collection.stream()、Collection.parallelStream()
- 通过Collection接口中的stream()方法获取数据源为集合的流对象【同步流】:
Stream<T> stream() = list.stream(); - 通过Collection接口中的parallelStream()方法获取数据源为集合的流对象【并发、异步流】:
Stream<T> parallelStream() = list.parallelStream();
public static void main(String[] args) {
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
System.out.println("创建一个顺序流");
stream.forEach(System.out::println);
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
System.out.println("创建一个并行流");
parallelStream.forEach(System.out::println);
}
/*
输出:创建一个顺序流
a
b
c
创建一个并行流
b
c
a
* */「stream和parallelStream的简单区分」: stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
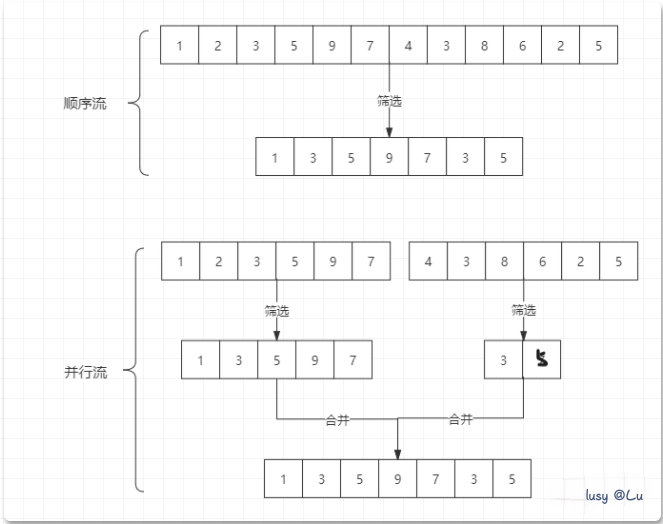
2.2.Arrays.stream()
- 通过Arrays工具类中的stream(T[] array)方法获取数据源为数组的流对象:
IntStream stream = Arrays.stream(array);[除了IntStream,还有LongStream、DoubleStream……]
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);2.3.Stream的静态方法
- 通过Stream工具类中的of(T… values)方法获取数据源为一堆零散数据的流对象:
Stream<T> stream = Stream.of(array); - 通过Stream工具类中的iterate(T seed, UnaryOperator f)方法获取数据源为无限的流对象,其中第一个参数是种子值,第二个参数是一个函数,用于生成后续的元素:
Stream<T> stream = Stream.iterate(0, n -> n + 2); - 通过Stream工具类中的generate(Supplier s)方法获取数据源为无限的流对象,其中参数是一个供应商函数,用于生成元素:
Stream<T> stream = Stream.generate(Math::random);
Stream<Integer> stream = Stream.of(1, 2, 3, 4);
stream.forEach(System.out::println);
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4); //limit(4)表示只取前4个元素
stream2.forEach(System.out::println);
Stream<Double> stream3 = Stream.generate(Math::random).limit(3); //limit(3)表示只取前3个元素
stream3.forEach(System.out::println);
/*输出结果:
使用Stream.of():
1
2
3
4
使用Stream.iterate():
0
3
6
9
使用Stream.generate():
0.34339747950763355
0.8263192360076247
0.6455630248922111 */2.4.文件创建
- BufferedReader.lines()方法获取数据源为文件的流对象:
Stream<String> stream = new BufferedReader(new FileReader(filePath)).lines(); - 通过Files工具类中的lines(Path path, Charset cs)方法获取数据源为文件的流对象:
Stream<String> stream = Files.lines(Paths.get(filePath), Charset.forName(charsetName));【安全性更强,推荐使用】
BufferedReader.lines() 和 Files.lines() 都是用于从文件中逐行读取数据的方法,但它们的用法和实现细节略有不同。前者需要手动创建 BufferedReader 对象,并在使用完后手动关闭流,而后者更为简洁,因为这个方法是Files工具类的一个静态方法,所以不需要手动创建对象,不需要手动关闭流
public static void main(String[] args) {
// 使用BufferedReader.lines()创建数据源为文件的流
try (BufferedReader br = new BufferedReader(new FileReader("input.txt"))) {
Stream<String> stream = br.lines();
stream.forEach(System.out::println);
} catch (IOException e) {
throw new RuntimeException(e);
}
// 使用Files.lines()创建数据源为文件的流
try {
Stream<String> lines = Files.lines(Paths.get("input.txt"));
// 等价于:Stream<String> lines = Files.lines(Path.of("input.txt"));
lines.forEach(System.out::println);
} catch (IOException e) {
throw new RuntimeException(e);
}
}2.5.其他
- Pattrn.splitAsStream(CharSequence input):是Pattern类中的一个方法,用于将字符串根据指定的正则表达式分割为流对象,其中参数为字符串,返回值为流对象。
- JarFile.stream():是JarFile类中的一个方法,用于将Jar文件中的条目(文件)转换为流对象,返回值为流对象。
public static void main(String[] args) {
// Pattrn.splitAsStream(CharSequence input)
// 定义正则表达式
String regex = "\\s+"; // 表示一个或多个空白字符
// 创建 Pattern 对象
Pattern pattern = Pattern.compile(regex);
// 使用 splitAsStream() 方法分割字符串并返回流,并对流进行遍历操作
pattern.splitAsStream("Java is a programming language").forEach(System.out::println);
// 使用JarFile.stream()
try (JarFile jarFile = new JarFile("a.jar")) {
Stream<JarEntry> entryStream = jarFile.stream();
entryStream.forEach(entry -> System.out.println(entry.getName()));
} catch (IOException e) {
throw new RuntimeException(e);
}
}3.中间操作
中间操作又可以分为无状态(Stateless)操作与有状态(Stateful)操作,前者是指元素的处理不受之前元素的影响;后者是指该操作只有拿到所有元素之后才能继续下去。
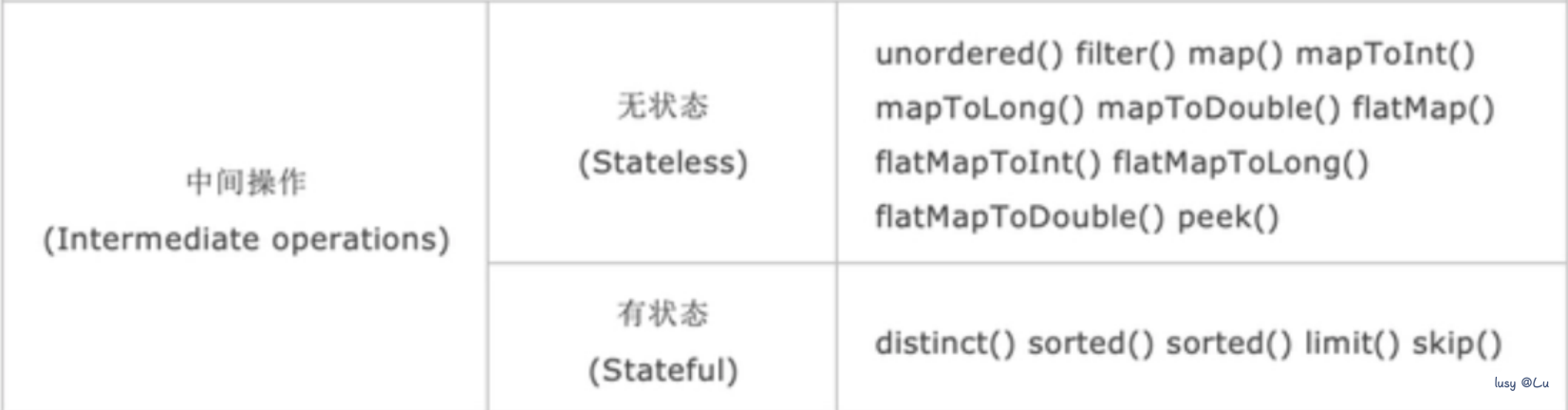
| 方法 | 作用 |
|---|---|
Stream<T> filter(Predicate<? super T> predicate) |
过滤流中的元素,返回符合条件的元素组成的流 |
Stream<T> distinct() |
元素去重,返回不含重复的元素的流 【依赖元素的hashCode()和equals()方法,注意判断是否需要进行重写】 |
Stream<R> map(Function<? super T, ? extends R> mapper) |
将流中的元素映射到另一个流中,返回映射后的流 【第一个类型是流中原本的元素类型,第二个类型是映射后的元素类型】 |
Stream<T> flatMap(Function<? super T, ? extends Stream<? extends T>> mapper) |
将流中的元素映射到另一个流中,返回映射后的流,其中映射后的流可以是多个元素组成的流,而不是单个元素。【第一个类型是流中原本的元素类型,第二个类型是映射后的流中元素的类型】 |
Stream<T> sorted() |
对流中的元素进行排序,返回排序后的流 |
Stream<T> sorted(Comparator<? super T> comparator) |
对流中的元素进行排序,返回排序后的流,其中参数为比较器,用于比较元素大小。【依赖元素的compareTo()方法,注意判断是否需要进行重写】 |
Stream<T> skip(long n) |
跳过前n个元素,返回剩余的元素组成的流 |
Stream<T> limit(long maxSize) |
截取前maxSize个元素,返回截取后的流 |
Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) |
将两个流合并为一个流,返回合并后的流 【如果a和b的类型不同,合并出来的会是他们共同的父类 |
Stream<T> peek(Consumer<? super T> action) |
对流中的元素进行操作,返回操作后的流,但不改变原流。【参数为消费者,用于对元素进行操作】 |
3.1.筛选、去重
filter()和distinct()方法用于筛选和去重流中的元素。
public static void main(String[] args) {
ArrayList<Person> array = new ArrayList<>();
Collections.addAll(array,
new Person("张三",23),
new Person("隔壁老王",25),
new Person("隔壁老王",25),
new Person("李四",24),
new Person("小思思",23));
System.out.println("用filter()筛选名字长度大于2的人物:");
array.stream().filter(p -> p.getName().length() > 2).forEach(System.out::println);
System.out.println("用distinct()去重:");
array.stream().distinct().forEach(System.out::println);
}
/*
用filter()筛选名字长度大于2的人物:
Person{name = 隔壁老王, age = 25}
Person{name = 隔壁老王, age = 25}
Person{name = 小思思, age = 23}
用distinct()去重:
Person{name = 张三, age = 23}
Person{name = 隔壁老王, age = 25}
Person{name = 李四, age = 24}
Person{name = 小思思, age = 23}
*/ 3.2.映射
3.2.1.map() 方法:
map()方法接受一个函数作为参数,该函数用于将流中的每个元素映射到另一个值。这个映射后的值可以是任何类型,最后返回的流包含这些映射后的元素。- 对于每个输入元素,
map()方法都会生成一个对应的输出元素。 map()方法返回的流与原始流的元素数量相同,但是每个元素都经过了映射函数的转换。
ArrayList<Person> array = new ArrayList<>();
Collections.addAll(array,
new Person("张三",23),
new Person("隔壁老王",25),
new Person("小思思",23));
// 调用map的方法一:
array.stream().map(new Function<Person, String>() {
public String apply(Person person) {
return person.getName();
}
}).forEach(System.out::println);
// 调用map的方法二(lambda表达式):
array.stream().map(p -> p.getName()).forEach(System.out::println);
// 调用map的方法三(方法引用)
array.stream().map(Person::getName).forEach(System.out::println);
/*
* 输出:
* 张三
* 隔壁老王
* 小思思
*/3.2.2.flatMap() 方法:
flatMap()方法也接受一个函数作为参数,但是这个函数的返回类型是一个流。这个函数会将流中的每个元素映射到另一个流。- 与
map()方法不同,flatMap()方法会将这些内部流合并成一个单一的流。内部流中的所有元素都会被合并到结果流中,形成一个扁平化的流。 flatMap()方法可以处理嵌套的流结构,即使每个元素映射后的流可能包含多个元素,最终返回的流也只是一个单一的流。
//首先初始化输入列表
List<String> list1 = List.of("1");
List<String> list2 = List.of("3");
List<String> list3 = List.of("2");
List<String > list4 =List.of("4","5");
List<List<String>> list = List.of(list1,list2,list3,list4);
//开始执行操作
List<String> listT = list.stream().flatMap(Collection::stream).collect(Collectors.toList());
System.out.println(listT);
/*
给定输入:[[1],[2],[3],[4,5]]
要求输出:[1,2,3,4,5]*/看一下具体的执行流程。橙色的是stream的通用执行流程,不管你中间态用哪个方法,这里是不变的,蓝色的是ArrayListSpliterator分割器。红色的执行流程是flatMap的执行流程。
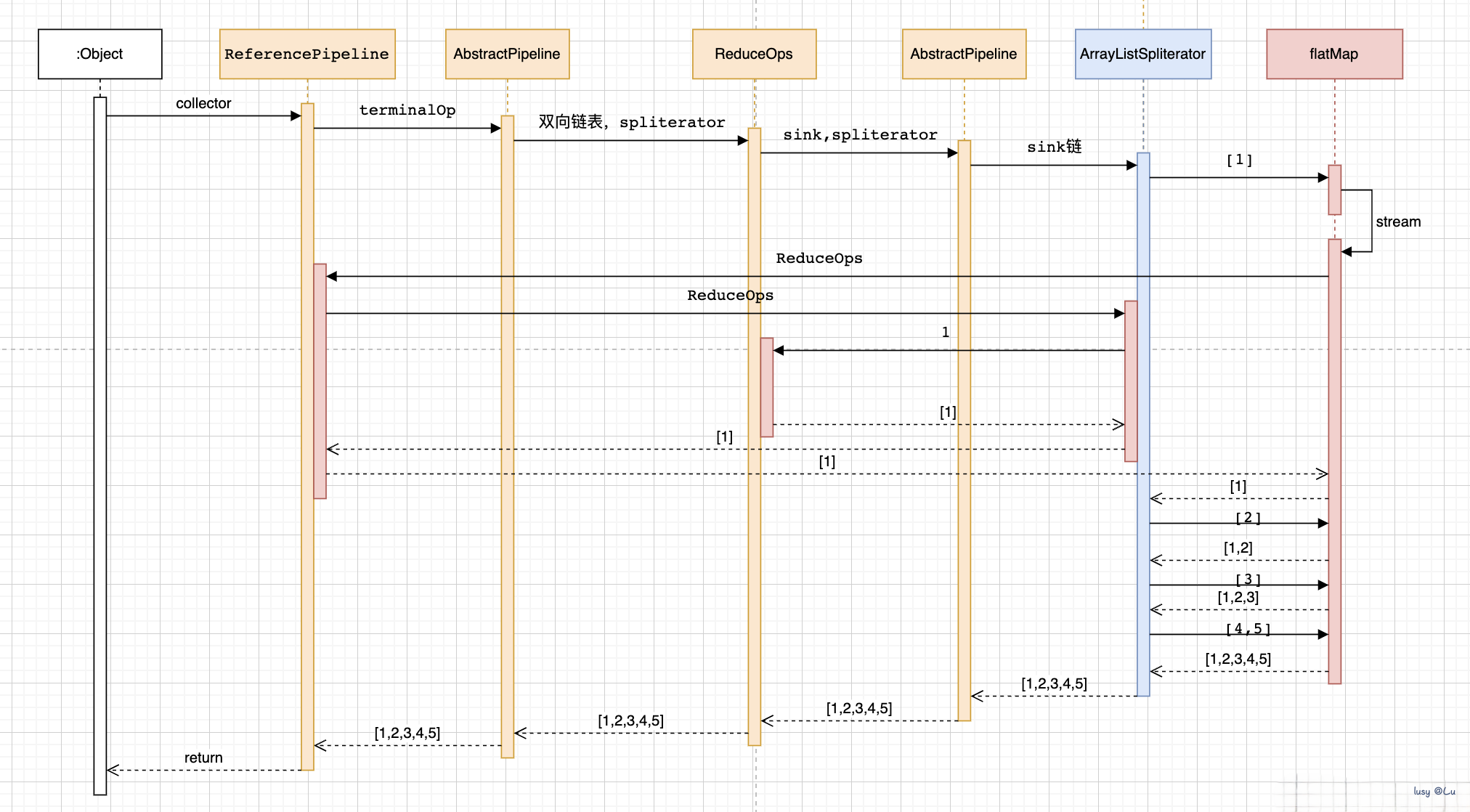
可以看到ArrayListSpliterator先取出第一个元素[1]这个一维数组传递给flatMap,然后flatMap执行了我们传入的Collection::stream方法,该方法是初始化一个stream头节点。也就是再生成了一个stream
重点就是这里了。再次把[1]这个一维数组放入了新的stream里面。然后把结果态节点ReduceOps传递给了新的stream作为新的stream的结果态节点。
这个时候新的stream开始执行ArrayListSpliterator。从而把[1]一维数组进行for循环,取出了其中的1这个元素,然后把1传入了同一个ReduceOps进行处理从而组成了一个结果list->[1]。
把步骤总结如下:
1.取出二维数组的第一个一维数组
2.把一维数组和结果态节点重新创建一个stream
3.执行stream把一维数组的元素循环放入结果态的list
循环二维数组,不断重复上述步骤,就可以把二维数组展开成一维数组了。
3.2.3.map()和flatMap()的区别
总的来说:
map()方法是一对一的映射,而flatMap()方法可以处理一对多的映射,可以将多个流合并成一个流。map()和faltMap()的参数差别在于,前者传入一个实体返回一个实体,后者则是传入一个实体返回一个Stream流,那既然是流,最好返回值本身就是一个Stream,或者能被转换成Stream的对象!
List<String> list = List.of("Holle world and you world");
// 调用flatMap的方法一:
list.stream().flatMap(new Function<String, Stream<String>>() {
public Stream<String> apply(String list) {
return Stream.of(list.split("\\s+"));
}
}).forEach(System.out::println);
// 调用flatMap的方法二:
list.stream().flatMap(t -> Stream.of(t.split("\\s+")))
.forEach(System.out::println);
/*
* 输出: Holle
* world
* and
* you
* world
* flatMap会把按空格拆分后所有的单词流合并成一个流返回.
* 这就意味着,当你调用 forEach(System.out::println) 方法时,它会直接作用于这个合并后的流上,
* 并打印出每个单词。
* */
//Map方法
list.stream().map(t -> Stream.of(t.split("\\s+")))
.forEach(System.out::println);
/*输出:java.util.stream.ReferencePipeline$Head@b1bc7ed
而Map方法最后的结果为一个地址,并没有对数组里面的结果进行细分,最后的结果依旧为一个整体
这是因为map里面的参数Stream.of(t.split("\\s+"))会将每个元素映射成一个流,
而map() 方法返回的是一个包含映射后元素的流对象,这个流没有重写`toString`方法
导致返回的是一个包含多个流的流,在使用.forEach方法时,默认打印对象的 toString() 方法的结果。
在这种情况下,由于没有重写 toString() 方法,所以它打印的是默认的对象地址信息。
因为list中只有一个元素,所以外部流对象只包含一个内部流对象,输出一个地址*/
/*list.stream().map(new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("\\s+");
}
}).forEach(System.out::println);*/
// 在return s.split("\\s+");会报错,是因为split()方法返回的是一个数组,而map()方法要求返回的是一个对象。map并不能处理一对多的映射 3.3.排序
sorted()方法用于对流中的元素进行排序。默认情况下,排序是按照自然顺序进行的,即升序。【其中的元素必须实现 Comparable 接口,否则会抛出 ClassCastException 异常】sorted(Comparator<T> comparator)方法用于对流中的元素进行排序,并指定排序规则。我们可以使用lambda表达式来创建一个Comparator实例。可以自定义排序规则。
#自然序排序一个list
list.stream().sorted()
#自然序逆序元素,使用Comparator 提供的reverseOrder() 方法
list.stream().sorted(Comparator.reverseOrder())
# 使用Comparator 来排序一个list
list.stream().sorted(Comparator.comparing(Student::getAge))
# 颠倒使用Comparator 来排序一个list的顺序,使用Comparator 提供的reversed() 方法
list.stream().sorted(Comparator.comparing(Student::getAge).reversed()) Comparator.thenComparing(Comparator<? super T> other): 实现多字段排序,如果第一个比较器比较结果相等,则使用第二个比较器进行比较。可以搭配使用Comparator.reverseOrder() 实现降序和升序
// 按年龄升序,如果年龄相等,再按零花钱升序
List<userInfo> userList3 = userList.stream()
.sorted(Comparator.comparing(userInfo::getAge).thenComparing(userInfo::getMoney))
.collect(Collectors.toList());
// 按年龄降序,如果年龄相等,再按零花钱降序
List<userInfo> userList3 = userList.stream()
.sorted(Comparator.comparing(userInfo::getAge).thenComparing(userInfo::getMoney,Comparator.reverseOrder()))
// 也可以等价于 .sorted(Comparator.comparing(userInfo::getAge).thenComparing(Comparator.comparing(userInfo::getMoney).reversed()))
.collect(Collectors.toList()); - 自定义排序规则
// 按照名字的长度排序,长的在前面。【如果使用compareTo,是按照字典序排序】
List<Person> list = new ArrayList<Person>();
Collections.addAll(list,
new Person("zhangsan",23),
new Person("lisi",24));
list.stream().sorted((s1, s2) -> s2.getName().length() - s1.getName().length() )
.forEach(System.out::println);3.4.跳过、截取
skip(long n):如果流的当前长度大于n,则跳过前n个;否则将会得到一个长度为0的空流。limit(long n):参数是一个long型,如果集合当前长度大于参数则进行截取;否则不进行操作。
public class Demo10StreamSkip {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.skip(2);
System.out.println(result.count()); // 1 :流中剩下 "周芷若"
}
}
public class Demo11StreamLimit {
public static void main(String[] args) {
Stream<String> original = Stream.of("张无忌", "张三丰", "周芷若");
Stream<String> result = original.limit(2);
System.out.println(result.count()); // 2:截取了 "张无忌" 和 "张三丰"
}
}3.5.结合
concat(Stream<? extends T> a, Stream<? extends T> b): 合并a和b两个流为一个流 【如果a和b的类型不同,合并出来的会是他们共同的父类】
备注:这是一个静态方法,与 java.lang.String 当中的 concat 方法是不同的。
public class Demo12StreamConcat {
public static void main(String[] args) {
Stream<String> streamA = Stream.of("张无忌");
Stream<String> streamB = Stream.of("张翠山");
Stream<String> result = Stream.concat(streamA, streamB);
result.forEach(System.out::println);
/*输出:
张无忌
张翠山 */
}
}3.6.调试
peek(Comsumer<? super T> action):它接受一个 Consumer 函数作为参数,该函数会被应用到流中的每个元素上。【不会销毁流对象】
这个方法通常用于调试或记录流中元素的中间状态,或者在调试代码时查看流中元素的值,而不会对流进行实际操作。
3.6.1.对流中的元素进行遍历
List<userInfo> userList = new ArrayList<>();
Collections.addAll(userList,
new userInfo(18,30),
new userInfo(18,34),
new userInfo(17,28));
// 调用peek()方法遍历流中的元素
List<userInfo> list = userList.stream().peek(System.out::println)
.collect(Collectors.toList());
System.out.println(list);
/*输出:
userInof{Age = 18, Money = 30}
userInof{Age = 18, Money = 34}
userInof{Age = 17, Money = 28}
[userInof{Age = 18, Money = 30}, userInof{Age = 18, Money = 34}, userInof{Age = 17, Money = 28}]
*/3.6.2.对流中的对象进行修改
在Java的Stream中,它实际上是对原始数据的引用。
- 对于基本数据类型:修改只会作用在
peek()方法的内部,因为基本数据类型是按值传递的,peek()方法中的参数是局部变量,对它们的修改不会影响到原始数据。所以,对基本数据类型进行的修改只会作用在peek()方法的内部。 - 对于引用数据类型:
- 对于不可变对象(如
String):对它们的操作会返回一个新对象,而不会修改原始数据。所以对不可变对象的操作也只会作用在peek()方法的内部,不会影响流中的数据或原始数据。 - 对于可变对象(如
StringBuilder、自己创建的类userInfo等):对它们的操作会直接修改原始数据。因此,对可变对象的操作会影响流中的数据以及原始数据。
- 对于不可变对象(如
对于流中的对象进行修改:
实际上,流中的操作不会直接修改原始数据,而是操作原始数据中的对象。这意味着对流中的对象进行的任何修改都会影响原始数据。然而,需要注意的是,如果流中的对象是不可变对象,对它们进行的修改只会影响到流中的对象,而不会修改原始数据。这种修改只会作用在peek()方法的内部,不会影响到原始数据。
// 流中对象是不可变对象String,对其修改只会作用在peek()方法内部,不会影响流中的数据或原始数据
List<String> list1 = new ArrayList<>();
list1.add("apple");
list1.add("banana");
list1.add("cherry");
list1.stream()
.peek(new Consumer<String>() {
@Override
public void accept(String s) {
s += "_suffix";
System.out.println(s);
}
}) // 修改字符串内容
.forEach(System.out::println);
System.out.println(list1);
/*输出:
apple_suffix
apple
banana_suffix
banana -> 这里的输出顺序是先运行一次peek()方法,再运行一次forEach()方法,这样子迭代下去的
cherry_suffix 因为中间操作peek()属于无状态,所以元素的处理不受之前元素的影响,会直接执行完整条流中的所有操作
cherry
[apple, banana, cherry]
*/
// 调用peek()方法遍历流中的对象,将用户的年龄加10,注意:这个修改会修改到流中数据和原始数据
List<userInfo> userList = new ArrayList<>();
Collections.addAll(userList,
new userInfo(18,30),
new userInfo(18,34),
new userInfo(17,28));
userList.stream().peek(userInfo -> userInfo.setAge(userInfo.getAge()+10))
.forEach(System.out::println);
System.out.println(userList);
/*输出:
userInof{Age = 28, Money = 30}
userInof{Age = 28, Money = 34}
userInof{Age = 27, Money = 28}
[userInof{Age = 28, Money = 30}, userInof{Age = 28, Money = 34}, userInof{Age = 27, Money = 28}]
*/
// 流中对象是StringBuilder类型,属于可变对象,对它们进行的操作会影响流中的数据以及原始数据。
List<StringBuilder> list = new ArrayList<>();
list.add(new StringBuilder("apple"));
list.add(new StringBuilder("banana"));
list.add(new StringBuilder("cherry"));
list.stream().peek(stringBuilder -> stringBuilder.append("apple"))
.forEach(System.out::println);
System.out.println(list);
/*输出:
appleapple
bananaapple
cherryapple
[appleapple, bananaapple, cherryapple]
*/3.6.3.peek()方法的时序图
针对前面的代码在peek()方法后执行forEach()方法时,输出顺序是先运行一次peek()方法,再运行一次forEach()方法,这样子迭代下去的这个问题,我们通过时序图来解释。
//首先初始化输入列表
List<String> list1 = List.of("1");
List<String> list2 = List.of("3");
List<String> list3 = List.of("2");
List<String > list4 =List.of("5","4");
List<List<String>> list = List.of(list1,list2,list3,list4);
//开始执行操作
List<String> listT = list.stream()
.flatMap(Collection::stream)
.peek(e -> System.out.println(e)).filter(x -> Integer.parseInt(x) > 2)
.peek(e -> System.out.println(e))
.collect(Collectors.toList());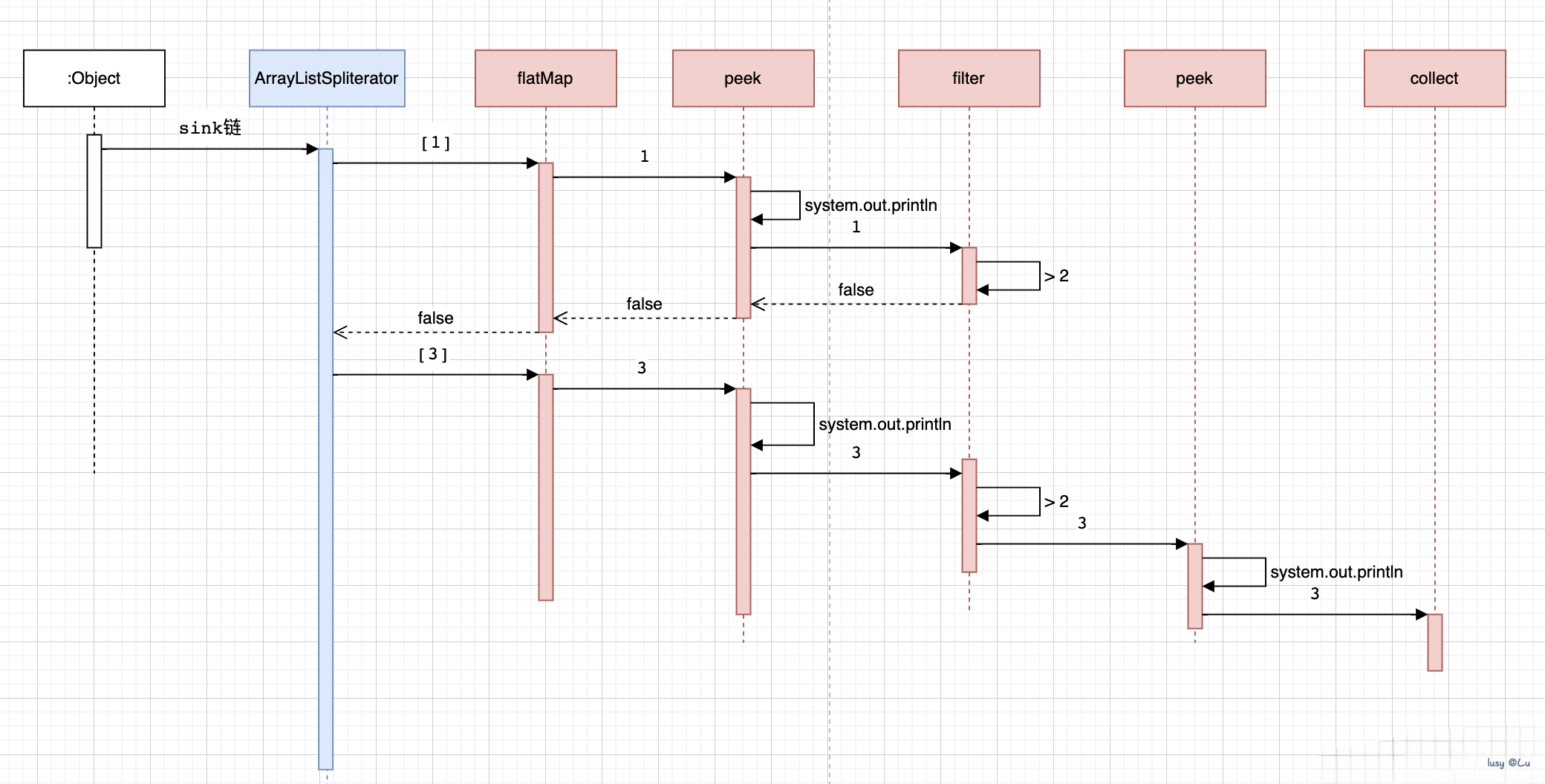
通过时序图我们可以发现,由于中间操作peek()、filter()和flatMap()都是属于无状态,所以在流(Stream)中,对于每个元素,会先执行完整条流中的所有操作,然后才处理下一个元素。这意味着,对于每个元素,先运行完整条流中的操作链,然后再处理下一个元素。而不是等待所有元素的某个操作完成后再进行下一个操作。
3.6.4.peek()方法的坑
-
坑一:peek() 不影响流的生成和消费
peek()是一个中间操作,它并不会终止流的处理流程,因此如果不跟一个终端操作(如collect(), forEach(), count()等),则peek()中的操作不会被执行,换言之,只有当流被消耗时,peek()里的操作才会真正发生。 -
坑二:peek() 的执行次数取决于下游操作
peek()方法中的动作会在流的每个元素上执行一次,但具体执行多少次取决于下游的终端操作。例如,如果你在排序(sorted())前使用了peek(),而在排序后又使用了一次peek(),则同一个元素可能会被两次peek()。 -
坑三:并发流中的peek()行为
对于并行流,peek()操作的执行顺序没有保证,而且可能会多次执行(取决于JVM的具体调度)。如果你在并行流中依赖peek()的顺序性或唯一性,可能会遇到意想不到的问题。 -
坑四:资源管理
如果在peek()中打开了一些资源(如文件、数据库连接等),但在peek()内部并未妥善关闭它们,可能会导致资源泄露。因为在没有终端操作的情况下,流可能不会立即执行,资源也就无法及时释放。 -
坑五:对流元素的修改可能无效
peek()通常用于读取或打印流元素,而不是修改它们。虽然理论上可以尝试在peek()中修改元素,但由于流的惰性求值和可能的不可变性,这样的修改可能不会反映到源集合或后续流操作中。 -
坑六:对于可变对象的处理可能会影响流中的数据和原始数据
peek()方法通常用于读取或打印流元素,而不是修改它们。然而,如果流中的元素是可变对象,并且在peek()中对其进行了修改,这些修改可能会影响到流中的数据以及原始数据。这是因为可变对象的特性使得对其进行的修改会在流中传递,可能会对后续的操作产生意外的影响。因此,在处理可变对象时,需要格外小心,并确保了解其对流处理的影响。
4.终结操作
结束操作又可以分为短路操作与非短路操作,前者是指遇到某些符合条件的元素就可以得到最终结果;而后者是指必须处理所有元素才能得到最终结果。

| 方法 | 作用 |
|---|---|
forEach(Consumer<? super T> action) |
遍历流中的元素,并对每个元素执行指定的操作。 |
findFirst() |
返回流中的第一个元素,如果流为空,则返回一个空的Optional对象。 |
findAny() |
返回流中的任意一个元素,如果流为空,则返回一个空的Optional对象。 |
anyMatch(Predicate<? super T> predicate) |
判断流中是否存在至少一个元素满足指定的条件。返回一个boolean值。 |
allMatch(Predicate<? super T> predicate) |
判断流中是否所有元素都满足指定的条件。返回一个boolean值。 |
noneMatch(Predicate<? super T> predicate) |
判断流中是否没有元素满足指定的条件。返回一个boolean值。 |
reduce(BinaryOperator<T> accumulator) |
将流中的元素按照指定的规则进行合并,返回合并后的结果。如果流为空,返回的 Optional 对象也为空。 |
reduce(T identity, BinaryOperator<T> accumulator) |
对流中的元素进行累积操作,使用指定的初始值,并返回累积结果。如果流为空,返回的是初始值。 |
max(Comparator<? super T> comparator) |
返回流中最大的元素,如果流为空,则返回一个空的Optional对象。 |
min(Comparator<? super T> comparator) |
返回流中最小的元素,如果流为空,则返回一个空的Optional对象。 |
count |
返回流中元素的数量【long类型】。 |
toArray() |
将流中的元素转换为数组,返回一个数组。 |
toList() |
将流中的元素转换为List,返回一个List。 |
collect(Collector<? super T, A, R> collector) |
将流中的元素收集到一个容器中,返回该容器。方法中的参数A和R表示中间结果容器的类型和最终结果的类型。 |
4.1.遍历
forEach(Consumer<? super T> action):遍历流中的元素,并对每个元素执行指定的操作。【打印、计算、转换……】
// forEach遍历打印
List<Integer> list1 = List.of(3, 2, 1, 4, 7, 10);
list1.forEach(System.out::println);
// forEach遍历求和
List<Integer> list2 = List.of(3, 2, 1, 4, 7, 10);
AtomicInteger sum = new AtomicInteger(); //将sum声明为AtomicInteger类型,因为AtomicInteger是原子性的,可以被匿名内部类访问。
list2.forEach((Integer num) -> sum.addAndGet(num));
System.out.println("Sum: " + sum); // 输出 Sum: 27
// forEach遍历实现字母小写到大写的转换
List<String> strings = List.of("apple", "banana", "cherry");
List<String> upperCaseStrings = new ArrayList<>();
strings.forEach((String s) -> upperCaseStrings.add(s.toUpperCase()));
System.out.println("Upper case strings: " + upperCaseStrings); // 输出 Upper case strings: [APPLE, BANANA, CHERRY]4.2.匹配
findFirst():返回流中的第一个元素,如果流为空,则返回一个空的Optional对象。findAny():返回流中的任意一个元素,如果流为空,则返回一个空的Optional对象。anyMatch(Predicate<? super T> predicate):判断流中是否存在至少一个元素满足指定的条件。返回一个boolean值。allMatch(Predicate<? super T> predicate):判断流中是否所有元素都满足指定的条件。返回一个boolean值。noneMatch(Predicate<? super T> predicate):判断流中是否没有元素满足指定的条件。返回一个boolean值。
List<Integer> list1 = List.of(3, 2, 1, 4, 7, 10);
System.out.println(list1.stream().findFirst());// 输出:Optional[3]
System.out.println(list1.stream().findAny()); // 输出:Optional[3]
System.out.println(list1.stream().anyMatch(x -> x % 3 == 0));// 输出:true
System.out.println(list1.stream().allMatch(x -> x % 3 == 0));// 输出:false
System.out.println(list1.stream().noneMatch(x -> x % 3 == 0));// 输出:false
// 如果流为空,则返回的 Optional 对象也为空。
List<Integer> list2 = List.of();
System.out.println(list2.stream().findFirst()); // 输出:Optional.empty
System.out.println(list2.stream().findAny());// 输出:Optional.empty
System.out.println(list2.stream().anyMatch(x -> x % 3 == 0));// 输出:false
System.out.println(list2.stream().allMatch(x -> x % 3 == 0)); // 输出:true
System.out.println(list2.stream().noneMatch(x -> x % 3 == 0));// 输出:true
// 如果list是null,在执行流操作时,会抛出NullPointerException异常。4.3.规约
reduce(BinaryOperator<T> accumulator):将流中的元素按照指定的规则进行合并,返回合并后的结果。如果流为空,返回的 Optional 对象也为空。- 参数:
BinaryOperator<T> accumulator,BinaryOperator继承于BiFunction, 这里实现BiFunction.apply(param1,param2)接口即可。支持lambda表达式,形如:(result,item)->{…} 。 - 返回值:返回Optional对象,由于结果存在空指针的情况(当集合为空时)因此需要使用Optional。
List<Integer> list=List.of(1,2,3,4,5); //将数组进行累加求和 //由于返回的是 Optional ,因此需要get()取出值。 Integer total=list.stream().reduce((result,item)->result+item).get(); System.out.println(total) // 输出:15 List<String> strings = List.of("Hello", " ", "World", "!"); // 使用 reduce 方法将字符串列表中的字符串拼接成一个新的字符串 String result = strings.stream().reduce("", (partialResult, str) -> partialResult + str); System.out.println(result); // 输出:Hello World!- 参数:
reduce(T identity, BinaryOperator<T> accumulator):对流中的元素进行累积操作,使用指定的初始值,并返回累积结果。如果流为空,返回的是初始值.- 参数1:T identity 为一个初始值(默认值) ,当集合为空时,就返回这个默认值,当集合不为空时,该值也会参与计算。
- 参数2:BinaryOperator
accumulator 这个与一个参数的reduce相同。 - 返回值:并非 Optional,由于有默认值 identity ,因此计算结果不存在空指针的情况。
List<Integer> list=List.of(1,2,3,4,5); Integer total=list.stream().reduce(0,(result,item)->result+item); System.out.println(total);//结果为:15 list=new ArrayList<>(); total=list.stream().reduce(0,(result,item)->result+item); System.out.println(total);//数组为空时,结果返回默认值0reduce(U identity, BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner):这个方法允许更复杂的规约操作,可以用于计算任意类型的累加器值,而不仅仅是原始数据类型。同时,由于存在并行执行的可能性,需要确保累加器函数和组合器函数的实现是线程安全的。- 第一个参数和第二个参数的定义同上,第三个参数比较特殊,后面慢慢讲。
- 可以看到该方法有两个泛型 T 和 U :
(1)泛型T是集合中元素的类型,
(2)泛型U是计算之后返回结果的类型,U的类型由第一个参数 identity 决定。
也就是说,三个参数的reduce()可以返回与集合中的元素不同类型的值,方便我们对复杂对象做计算式和转换。
其实这相当于List<Person> list= List.of( new Person("张三",1) ,new Person("李四",2) ,new Person("王五",3) ,new Person("小明",4) ,new Person("小红",5)); Integer total=list.stream() .reduce( Integer.valueOf(0) /*初始值 identity*/ ,(integer, person)->integer+ person.getAge() /*累加计算 accumulator*/ ,(integer1,integer2)->integer1+integer2 /*第三个参数 combiner*/ ); System.out.println(total);//结果:15Integer total=list.stream().mapToInt(Person::getAge).sum(); System.out.println(total);//结果也是:15
第三个参数 BinaryOperator<U> combiner 是个什么鬼?
这个参数的lambda表达式我是这么写的:(integer1,integer2)->integer1+integer2
现在我将其打印出来:
Integer total=list.stream()
.reduce(
Integer.valueOf(0)
,(integer, person)->integer+ person.getAge()
,(integer1,integer2)-> {
//这个println居然没有执行!!!
System.out.println("integer1=" + integer1 + ", integer2=" + integer2);
return integer1 + integer2;
}
);
System.out.println(total);//结果:15发现这个参数的lambda表达式根本就没有执行?!
我换了一种方式,换成 parallelStream ,然后把线程id打印出来:
Integer total=list.parallelStream()
.reduce(
Integer.valueOf(0)
,(integer, person)->integer+ person.getAge()
,(integer1,integer2)-> {
//由于用的 parallelStream ,可发生并行计算,所以我增加线程id的打印:
System.out.println("threadId="+Thread.currentThread().getId()+", integer1="+integer1+", integer2="+integer2);
return integer1 + integer2;
}
);
System.out.println(total);
/*结果如下:
threadId=1, integer1=4, integer2=5
threadId=30, integer1=1, integer2=2
threadId=1, integer1=3, integer2=9
threadId=1, integer1=3, integer2=12
15*/把 stream 换成并行的 parallelStream,
可以看出,有两个线程在执行任务:线程1和线程30 ,
每个线程会分配几个元素做计算,
如上面的线程30分配了元素1和2,线程1分配了3、4、5。
至于线程1为什么会有两个3,是由于线程30执行完后得到的结果为3(1+2),而这个3又会作为后续线程1的入参进行汇总计算。
可以多跑几次,每次执行的结果不一定相同,如果看不出来规律,可以尝试增加集合中的元素个数,数据量大更有利于并行计算发挥作用。
因此,第三个参数 BinaryOperator<U> combiner 的作用为:汇总所有线程的计算结果得到最终结果,
并行计算会启动多个线程执行同一个计算任务,每个线程计算完后会有一个结果,最后要将这些结果汇总得到最终结果。
我们再来看一个有意思的结果,把第一个参数 identity 从0换成1:
Integer total=list.parallelStream()
.reduce(
Integer.valueOf(1)
,(integer, person)->{ System.out.println("$ threadId="+Thread.currentThread().getId()+", integer="+integer+", scoreBean.getScore()="+person.getAge());
return integer+ person.getAge();}
,(integer1,integer2)-> {
//由于用的 parallelStream ,可发生并行计算,所以我增加线程id的打印:
System.out.println("threadId="+Thread.currentThread().getId()+", integer1="+integer1+", integer2="+integer2);
return integer1 + integer2;
}
);
System.out.println(total);
/*结果如下:
$ threadId=30, integer=1, scoreBean.getScore()=2
$ threadId=1, integer=1, scoreBean.getScore()=3
$ threadId=32, integer=1, scoreBean.getScore()=5
$ threadId=33, integer=1, scoreBean.getScore()=4
$ threadId=31, integer=1, scoreBean.getScore()=1
threadId=33, integer1=5, integer2=6
threadId=31, integer1=2, integer2=3
threadId=33, integer1=4, integer2=11
threadId=33, integer1=5, integer2=15
20*/预期结果应该是16(初始值1+原来的结果15),但实际结果为20,多加了4次1,猜测是多加了四次初始值,
从打印的结果可以发现:
(1)并行计算时用了5个线程(线程id依次为:30, 1, 32, 33, 31),汇总合并时用了两个线程(线程id为33和31)
(2)并行计算的每一个线程都用了初始值参与计算,因此多加了4次初始值。
总结:
使用 parallelStream 时,初始值 identity 应该设置一个不影响计算结果的值,比如本示例中设置为 0 就不会影响结果。
我觉得这个初始值 identity 有两个作用:确定泛型U的类型和避免空指针。
但是如果初始值本身就是一个复杂对象那该怎么办呢?
比如是初始值是一个数组,那么应该设定为一个空数组。如果是其他复杂对象那就得根据你reduce的具体含义来设定初始值了。combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t) //combiner.apply(u1,u2) 接收两个相同类型U的参数 //accumulator.apply(u, t) 接收两个不同类型的参数U和T,U是返回值的类型,T是集合中元素的类型 //这个等式恒等,parallelStream计算时就不会产生错误结果
4.4.聚合
max(Comparator<? super T> comparator): 返回流中最大的元素,如果流为空,则返回一个空的Optional对象。max(Comparator<? super T> comparator): 返回流中最小的元素,如果流为空,则返回一个空的Optional对象。count(): 返回个数【long类型】
List<Integer> list = List.of(3,2,4,5,1);
System.out.println(list.stream().max(Integer::compare));// 输出:Optional[5]
System.out.println(list.stream().min(Comparator.comparing(Integer::intValue)).get());// 输出:1
System.out.println(list.stream().count());// 输出:5
list = List.of();
System.out.println(list.stream().max(Integer::compare));// 输出:Optional.empty4.5.收集
4.5.1.toArray
toArray(): 返回一个Object[]数组,其中包含Stream中的所有元素。toArray(IntFunction<A[]> generator):可以指定返回数组的类型。参数 generator 是一个数组生成器函数,它根据提供的数组长度创建一个新数组。这使得我们可以在返回的数组中指定元素的类型。
List<Person> list = List.of(
new Person("张三",23),
new Person("李四",24),
new Person("王五",25)
);
Object[] array1 =list.stream().toArray();
System.out.println(Arrays.toString(array1));
// 输出:[Person{name = 张三, age = 23}, Person{name = 李四, age = 24}, Person{name = 王五, age = 25}]
Person[] array2 = list.stream().toArray(v -> new Person[v]);
System.out.println(Arrays.toString(array2));
// 输出:[Person{name = 张三, age = 23}, Person{name = 李四, age = 24}, Person{name = 王五, age = 25}]4.5.2.toList
toList(): 返回一个包含Stream中所有元素的List。
List<Integer> list = Stream.of(32, 11, 23, 434, 54).toList();
System.out.println(list);
// 输出:[32, 11, 23, 434, 54]4.5.3.collect
collect(Collector<? super T, A, R> collector): 将Stream中的元素收集到一个容器中,并返回该容器。
4.5.3.1.统计
Collectors.counting(): 返回流中元素的个数。Collectors.summingInt(ToIntFunction<? super T> mapper): 返回流中元素的和。Collectors.summingDouble(ToDoubleFunction<? super T> mapper): 返回流中元素的和。Collectors.summingLong(ToLongFunction<? super T> mapper): 返回流中元素的和。Collectors.averagingInt(ToIntFunction<? super T> mapper): 返回流中元素的平均值。Collectors.averagingDouble(ToDoubleFunction<? super T> mapper): 返回流中元素的平均值。Collectors.averagingLong(ToLongFunction<? super T> mapper): 返回流中元素的平均值。
List<Integer> numbers = List.of(1, 2, 3, 4, 5);
// 个数
Long collect = numbers.stream().collect(Collectors.counting());
System.out.println("collect = " + collect);// collect = 5
// 求和
int sum = numbers.stream().collect(Collectors.summingInt(Integer::intValue));
System.out.println("Sum: " + sum);// Sum: 15
// 平均值
double average = numbers.stream().collect(Collectors.averagingInt(Integer::intValue));
System.out.println("Average: " + average);// Average: 3.04.5.3.2分组
Collectors.groupingBy(Function<? super T, ? extends K> classifier): 根据给定的分类函数对Stream中的元素进行分组,并返回一个Map,其中键是分类函数的结果,值是包含对应分类的元素的List。Collectors.partitioningBy(Predicate<? super T> predicate): 根据给定的断言函数对Stream中的元素进行分区,并返回一个Map,其中键是true和false,值是包含对应分类的元素的List。
List<String> words = List.of("apple", "banana", "orange", "grape", "cherry");
// 按单词的首字母分组
Map<Character, List<String>> groupedByFirstLetter = words.stream()
.collect(Collectors.groupingBy(word -> word.charAt(0)));
System.out.println("Grouped by first letter: " + groupedByFirstLetter);
// 输出:Grouped by first letter: {a=[apple], b=[banana], c=[cherry], g=[grape], o=[orange]}
// 按单词的长度进行分区
Map<Boolean, List<String>> partitionedByLength = words.stream()
.collect(Collectors.partitioningBy(word -> word.length() > 5));
System.out.println("Partitioned by length (>5): " + partitionedByLength);
//输出:Partitioned by length (>5): {false=[apple, grape], true=[banana, orange, cherry]}4.5.3.3连接
Collectors.joining(CharSequence delimiter): 将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
List<Person> list = List.of(
new Person("张三",23),
new Person("李四",24),
new Person("王五",25)
);
String collect = list.stream().map(p -> p.getName()).collect(Collectors.joining(","));
System.out.println(collect);// 张三,李四,王五
List<String> list1 = List.of("A","B","C");
String collect1 = list1.stream().collect(Collectors.joining("-"));
System.out.println(collect1);// A-B-C4.5.3.4.规约
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
Collectors.reducing(BinaryOperator<T> op):这是最基本的reducing方法。它接受一个二元运算符,对流中的所有元素进行归约。该方法将返回一个收集器Optional,它使用提供的运算符对流中的元素进行归约。Collectors.reducing(T identity, BinaryOperator<T> op):此方法是reducing方法的扩展,允许你指定一个初始值。提供的初始值将用作归约操作的起始值。如果流为空,则结果将是提供的初始值。Collectors.reducing(U identity, Function<? super T, ? extends U> mapper, BinaryOperator<U> op):这个方法允许你在进行归约之前先将元素映射到另一种类型。你可以指定一个映射函数,并提供一个初始值。然后,它将使用映射函数将元素映射为指定类型,再使用提供的初始值对映射后的结果进行归约。
List<Integer> list = List.of(1, 2, 3, 4);
// 只传一个参数:定义运算规则
System.out.println(list.stream().collect(Collectors.reducing(Integer::sum)));// Optional[10]
// 等价于:System.out.println(list.stream().reduce(Integer::sum));
// 传递两个参数:定义一个初始值和运算规则
System.out.println(list.stream().collect(Collectors.reducing(0, Integer::sum)));// 10
// 等价于:System.out.println(list.stream().reduce(0, Integer::sum));
// 传递三个参数:定义一个初始值、映射函数和运算规则
System.out.println(list.stream().collect(Collectors.reducing(0, x -> x * x, Integer::sum))); //10
// 等价于:System.out.println(list.stream().map(x -> x * x).reduce(0, Integer::sum));先映射在规约4.5.3.5.归集
Collectors.toList(): 将Stream中的元素收集到一个List中,并返回该List,元素可以重复,有序。Collectors.toSet(): 将Stream中的元素收集到一个Set中,并返回该Set,元素不能重复,无序Collectors.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper): 将Stream中的元素收集到一个Map中,并返回该Map。如果键重复会抛出 IllegalStateException 异常- 参数一表示键的生成规则
- 参数二表示值的生成规则
- Function
- 泛型一:表示流中每一个数据的类型
- 泛型二:表示Map集合中键的数据类型
- 重写方法apply
- 形参:依次表示流里面的每一个数据
- 方法体:生成键/值的代码
- 返回值:已经生成的键/值
Collectors.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction): 收集到 Map 集合中,允许指定一个合并函数来处理键冲突。
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "张无忌-男-15", "周芷若-女-14", "赵敏-女-13", "张强-男-20",
"张三丰-男-100", "张翠山-男-40", "张良-男-35", "王二麻子-男-37", "谢广坤-男-41");
//收集List集合当中
//需求:
//我要把所有的男性收集起来
List<String> newList1 = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toList());
System.out.println(newList1);// [张无忌-男-15, 张强-男-20, 张三丰-男-100, 张翠山-男-40, 张良-男-35, 王二麻子-男-37, 谢广坤-男-41]
//收集Set集合当中
//需求:
//我要把所有的男性收集起来
Set<String> newList2 = list.stream().filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toSet());
System.out.println(newList2);// [张强-男-20, 张良-男-35, 张三丰-男-100, 张无忌-男-15, 谢广坤-男-41, 张翠山-男-40, 王二麻子-男-37]
//收集Map集合当中
//我要把所有的男性收集起来
//键:姓名。 值:年龄
Map<String, Integer> map = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
new Function<String, String>() {
@Override
public String apply(String s) {
return s.split("-")[0];
}
},
new Function<String, Integer>() {
@Override
public Integer apply(String s) {
return Integer.parseInt(s.split("-")[2]);
}
}));
System.out.println(map); // {张强=20, 张良=35, 张翠山=40, 王二麻子=37, 张三丰=100, 张无忌=15, 谢广坤=41}
// lambda表达式简化
Map<String, Integer> map2 = list.stream()
.filter(s -> "男".equals(s.split("-")[1]))
.collect(Collectors.toMap(
s -> s.split("-")[0],
s -> Integer.parseInt(s.split("-")[2])));
System.out.println(map2); // {张强=20, 张良=35, 张翠山=40, 王二麻子=37, 张三丰=100, 张无忌=15, 谢广坤=41}
// 收集到 Map 集合中,处理键冲突
List<Person> persons = List.of(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Alice", 35)
);
Map<String, Integer> personMapWithMergeFunction = persons.stream()
.collect(Collectors.toMap(Person::getName, Person::getAge, (existing, replacement) -> existing));// 如果已经存在,保留原先存在的值
System.out.println(personMapWithMergeFunction); // {Alice=30, Bob=25}
5.Java Stream 底层实现
参考文章:深入理解Java Stream流水线



